
티스토리 뷰
의료 데이터 현황
의료데이터에서 가장 중요한것은 데이터 수집이다. 개인정보 정책에 의해 과거에는 데이터 수집이 불가능했었다. 그러나 2020.01에 법안이 통과 되면서, 가명정보(개인 식별이 불가능한 데이터)를 사용 할 수 있게 됐다. 즉, 민간 연구자에게 데이터 제공이 가능해 짐에 따라 바이오 데이터 분석가 들이 유망해지고 있고. 의료 데이터의 수집도 탄력을 받아 발전하고 있다.
Confusion matrics
사실 이글을 적은 이유는 바로 이부분을 적기 위함이다. 의료데이터를 분석하기 위해서는 Accuracy, Precision, Recall의 차이점에 대해 이해를 해야한다.
1. Confusion Matrix
모형을 예측하는 값에는 True와 False가 있다. 그리고 아래의 그림과 같이 모형의 예측값과 실제 값을 각각 축으로 하는 2x2 매트릭스로 표현한 것을 Confusion Matrix라고 부른다.
| T 예측값 F |
TP (True Positive) |
FP (False Positive) |
|
FN (False Negative) |
TN (True Negative) |
||
T F 실제값 |
|||
2. 정확도(Precision)
True로 예측한 분석대상 중에서 실제 값이 True인 비율을 말하며, 모형의 정확성을 나타내는 지표가 된다. 정확도가 높다는 것은 False Positive(실제 False를 True로 잘못 예측) 오류가 적다는 말이다.
| Precision = TP / (TP+FP) |
3. 재현율(Recall)
실제 값이 True인 분석대상 중에서 True로 예측하여 모형이 적중한 비율을 말하며, 모형의 완전성을 나타내는 지표이다. 재현율이 높다는 것은 False Negative(실제 True를 False로 잘못 예측) 오류가 낮다는 뜻이다.
| Recall = TP / (TP+FN) |
4. F1 지표(F1-score)
정확도와 재현율이 균등하게 반영될 수 있도록 정확도와 재현율의 조화평균을 계산한 값으로, 모형의 예측력을 종합적으로 평가하는 지표이다. 값이 높을수록 분류 모형의 예측력이 좋다고 말할 수 있다.
| F1 score = 2* ( Precision * Recall ) / ( Precision + Recall ) |
의료 데이터에서의 confusion matrix
의료 데이터에서는 Recall 이 중요하다 왜냐하면, 병걸린 사람을 검사했을 때 오진이 나오면 안되기 때문이다. 기본적으로 병원에서는 True/False(병의 유무)를 여러단계를 거쳐서 검사를 진행한다. 우선은 비교적 간단하지만, 정확도가 떨어지는 test를 먼저 진행한다. 그리고 병에 걸릴 가능성이 있다면 재검사를 통해 정확도가 높은 test를 진행는 방식을 사용한다. 예를들면, MRI를 찍고 다른 가능성이 있으면 혈액검사 같은 추가 검사를 진행하는 것과 같다. 정리하면, 처음부터 모든 검사를 다할 수없으니 간단한 검사부터 해서 좁혀나가는 것이다. 이러한 방식은 Recall이 좋아야 병을 찾아 나갈 수 가 있다.
물론 최종적으로는 Recall과 Precision이 둘다 좋은 비싼 방법을 사용할 것이다. 그러나 초반의 경우, 데이터를 쉽게 얻을 수 있는 것들을 조합하거나 recall을 더 중요시 한다. 여기서 주의 할 점이 Recall만 100프로 몰빵을 하면, Precision이 0이 될 수도 있다. 예를들면, 무한대의 환자가 왔을때 너 무조건 병이 있다고 하면 Recall은 100%가 된다. 하지만 Precision은 n/무한대 가 되므로 0으로 가까워진다. 병안 걸린 사람도 병린사람이 될기도 한다. 따라서 recall을 100프로 만드는 것은 바람직하지 않고, 0.9나 95%이상으로 유지하면서 precision을 떨어뜨리지 않는것이 중요하다.
Precision, recall 관계 확인 방법
Recall을 유지하면서 얼마나 큰 Precision을 유지할 수 있는가를 확인하는 방법은 다음과 같다.
from sklearn.metrics import plot_precision_recall_curve
fig = plt.figure() # figure하나를 만들어 주자.
ax = fig.gca() # gca를 사용해서 ax를 사용할 수 있다.
plot_precision_recall_curve(model_lr, X_test, y_test, ax=ax)
plot_precision_recall_curve(model_xgb, X_test, y_test, ax=ax)
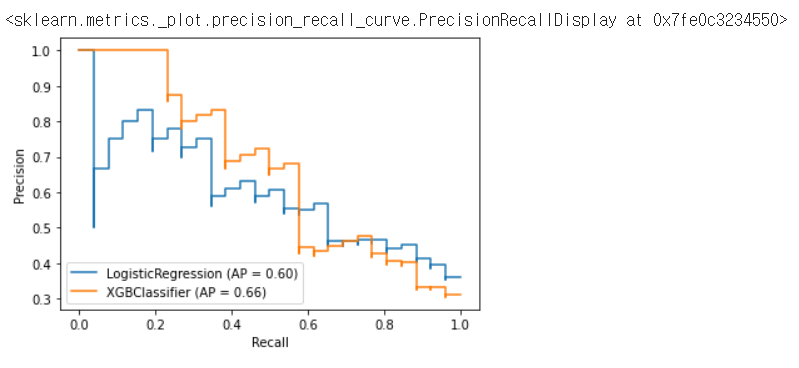
만약 다음과 같은 결과가 나왔다면, XGBClassifier가 일반적으로 로지스틱회귀보다 위쪽에 있는것을 토대로 XGB분류가 일반적으로 좋은 성능을 만들고 있다는 것을 알 수 있다
ROC 커브 확인하기
from sklearn.metrics import plot_roc_curve
fig = plt.figure()
ax = fig.gca()
plot_roc_curve(model_lr, X_test, y_test, ax=ax)
plot_roc_curve(model_xgb, X_test, y_test, ax=ax)
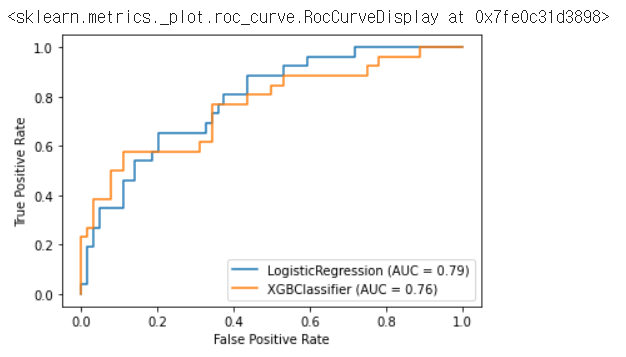
위 그림을 예로 보면 True Positive Rate와 False Positive Rate 2가지가 나오는 것을 알 수 있다.
우리의 목적은 False Positive Rate(참이라 예측했는데 거짓인 비율)를 낮게 유지하고 싶은 것이다.따라서 False Positive Rate가 빨리 증가하면서 빨리 1에 가까워지는 것을 보고 싶은거다. 따라서 위쪽에있는게 더 좋은거다. 위의 경우는 로지스틱 회기가 더 좋은 걸로 나온다.
'데이터분석' 카테고리의 다른 글
| [데이터분석] statsmodels을 활용한 선형 회귀분석 (3) | 2021.06.01 |
|---|---|
| [kaggle] 의료데이터_심부전증 예방하기 (0) | 2021.04.30 |
| [데이터 분석] 비전공자를 위한 ACF(Autocorrelation Function) 설명하기 (0) | 2021.04.07 |
| [데이터분석] 비전공자를 위한 QQ-Plot 설명하기 (0) | 2021.04.05 |
| [데이터분석] 정규화 방법론(Regression, Ridge, Lasso) (0) | 2021.04.03 |
- Total
- Today
- Yesterday
- login
- read_csv
- 자료구조
- pandas
- nextjs autoFocus
- 자연어처리
- logout
- useHistory 안됨
- useState
- django
- Deque
- react
- 클라우데라
- JavaScript
- mongoDB
- NextJS
- vuejs
- error:0308010C:digital envelope routines::unsupported
- TensorFlow
- Python
- Vue
- nodejs
- Express
- react autoFocus
- next.config.js
- UserCreationForm
- DFS
- Queue
- BFS
- typescript
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |