
티스토리 뷰
0. 들어가면서
NLP에 대해서는 할 이야기가 상당히 많다. 그러나 상세히 설명하기엔 너무 복잡하므로 간단히 하고 추가는 다른 페이지로 하겠다. NLP는 단어 문장 문서로 이야기를 많이 한다.
Word, Sentence, and Document Embedding
말의 가장 작은 단위가 word고 word가 모여서 Sentence가 되고 Sentence가 모여서 Document가 된다. 모든 과정에서 의미를 추출하는 것이 NLP의 궁극적인 목표이고, 그것을 어떻게 하는지에 대해 가장 중요하게 연구되는 부분이 Embedding이다. 그중에서 오늘은 word Embedding에 대해서만 볼 거다.
word Embedding
단어 하나에 대해서 꽤 많은 dimension을 가진 벡터로 표현을 하는 것이다. 앞에서 공부했었던 NB(naive bayers)에서 BOW를 배웠는데 거기서는 단어가 몇 번이나 나오는지만 중요(One-hot 방식)했다. 이러한 방법으로는 단어들 간의 관계를 알 수가 없다. 그래서 나온 것이 Word Vector Representations이다.
ex_ 특정 단어 dog를 표현하는 2가지 방식
Continuous (dense) Vector Representations => [6.2, 1.0, 2.4, 3.3,..., 3.5]
One-hot Vector Representations => [0.0, 1.0, 0.0, 0.0,..., 0.0]
vector로 표현하는 이유
hi와 hello가 비슷하다. dog랑 cat랑 비슷하다. 이러한 비슷 한 단어들은 vector 공간에서 표현하면 dog와 cat랑은 비슷한 공간에 있다. 그리고 dog에 s를 붙이면 dogs가 되고 cat에 s를 붙이면 cats가 되는데 복수형으로 바뀌는 것은 vector 공간에서 같은 방향으로 이동한다. 각각의 나라의 수도를 봐도 같은 방향으로 움직이고 관련 단어는 가까이에 있다. 이러한 것을 word embedding space라고 한다. dimention이 50이면 50차원으로 볼 수 있는데, 그 많은 차원 속에서 비슷하게 움직이는 것을 할 수 있다.
Distributed Representations
단어를 볼 때 하나의 컨셉이 많은 뉴런으로 표현이 되고 하나의 뉴런은 여러 컨셉을 표현한 수 있다. 즉, 뉴런과 컨셉은 many-to-many관계이다. vector로 보면 배열의 인덱스가 컨셉이라 볼 수 있다. 배열 전체가 하나의 단어라고 보면 된다.
Distributed Representations of Words
데이터 셋으로 워드를 학습을 하고 나면, Semantic(의미적인) and syntactic(문법적인) 특징들이 vector로 나타난다.
Distributed Representation은 Distributional Hypothesis에서 온것인데, 문맥을 보면 단어의 뜻을 알 수 있다는 말이다. 즉 같은 문맥에서 나온 단어는 유사한 의미를 가지고 있을 것이다. 여러 문맥을 고려하다 보면 유사한 단어는 가까운 vector 공간에 있게 된다는 것이 Distributional Hypothesis이다.
Word2Vec
실제로 wordvector를 학습한 것들 중에 가장 유명한 것이 word2vec이다.

Word2Vec은 두 가지 버전이 있다. CBOW와 Skip-Gram의 차이점은 뉴런 네트워크를 학습을 할 때, 어떤 가정으로 학습을 하냐에 달렸다. CBOW는 문맥 가운데 비어있는 단어를 예측하는 것이고, Skip-Gram은 주어진 단어의 양옆을 예측하는 것이다. 쉽게 말하면 dog를 정해진 차원의 vector로 만들 건데 vector에 어떤 숫자들을 넣어야 주위의 단어들을 예측을 잘할 수 있냐가 포인트다.

Evaluation : Word Similarity Task
유사한 의미를 가진 단어가 유사한 공간에 나오고, 방향성이 잘 나오면 학습을 잘했다고 판단한다. 학습을 했을 때, 어떻게 Evaluation 하는지 2가지로 알아보자. 첫 번째가 Word Similarity Task이다

Human Evaluation - word1과 word2가 얼마나 유사한지 사람이 평가한 것이다.
Consine Similarity - 2개의 vector를 코사인으로 얼마나 가까운지 거리를 계산한 것이다.
훈련한 모델이 괜찮다면 Human Evaluation과 Consine Similarity가 비슷하게 나와야 한다.
Evaluation: Word Analogy Task
단어들 간의 관계를 나타낸다. a:b의 관계는 어떤 단어의 a':b'와 같은가를 찾고 b'를 지운 후에 b'를 모른다고 가정한 후에 a에서 b로 이동하는 vector를 찾고 a'에서 그 vector만큼 이동 후에 b'를 얼마나 잘 찾아내는지를 확인하여 평가한다.

Word embedding의 문제점
문제점 1. Unseen words
- Morphologically rich languages - 나의 학습 데이터에 단어가 나오지 않았으면 vector공간에 어디에 단어가 있는지 알 수가 없다. ex) 예쁘다, 예쁜, 예쁨, 예뻤다. 이러한 단어들이 같은 단어라는 것을 컴퓨터는 알 수가 없다. input으로 넣을 때는 다 다른 단어로 들어간다.
- Compositionality of words - 새로운 단어를 정의를 내릴 수 있다. ex) 미인 = 예쁜 사람. '예쁜'이라는 단어와 '사람'이라는 단어를 학습했다면, 미인이란 단어를 학습 시 못 봤더라도 '예쁜'과 '사람'이라는 단어를 합치면 미인이라는 것을 알 수가 있어야 한다.
즉, word embedding을 하면 위의 문제를 찾아낼 수 없다.
문제점 2. Quality of vectors assiged to rare words
미인이라는 단어가 학습 데이터에 있지만 100만 개의 단어 중 2개밖에 안 나왔다면, word vector를 학습을 해도 퀄리티가 별로 안 좋을 수 있다.
이러한 문제의 해결책으로 word 뿐만 아니라 다른 유닛에 대해서도 임베딩을 한다. 그러한 대표적인 예가 FastText(페이스북)에서 만든 Subword Information Skip-Gram이다.
Subword Information Skip-Gram (a.k.a. FastText)
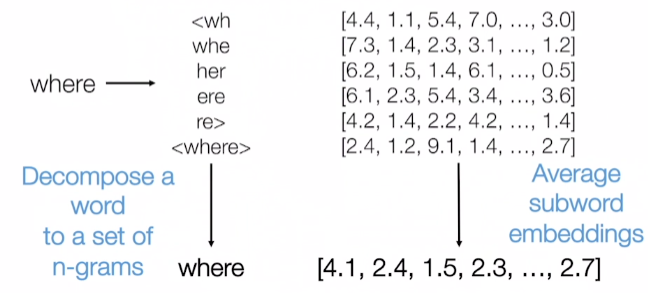
subword information skip-gram이란 where이라는 단어가 있다면 위의 그림의 내용처럼 잘라서 전부다 모델링을 하는 거다. 이것을 한국어로 생각하면 'ㅇ' 'ㅖ' 'ㅃ' 'ㅡ' 'ㅁ'으로 하나씩 쪼개서 인접한 전체의 경우의 수를 모델링을 하는거다. 이런 식으로 하면 훨씬 더 잘 되고 새로운 단어에 대해 예측이 더 잘 된다. 실제로 일반 Skip-Gram보다 FastText를 한 것이 비슷한 단어를 훨씬 더 잘 찾는다.

위의 사진이 query 부분의 단어를 줬을 때 FastText(sisg) 부분이 비슷한 부분을 찾은 것과 일반 Skip-Gram(sg)이 비슷한 부분을 찾은 것을 보면 FastText 부분이 훨씬 더 정확한 것을 알 수 있다.
여기까지가 Word Embedding이다.
Word Embedding도 최근에도 많이 쓰이고 유용한 방법이긴 하다. 그러나 Neural Network을 이용해 language를 다루는 것에 큰 발전이 있었고 그게 바로 ELMo와 BERT이다.
Contextualized Word Embedding
Deep contextualized word representations (NAACL 2018)
Embeddings form Language Models (ELMo)
Word Embedding의 가장 큰 문제가 context가 없다는 것이다. 아래의 예를 보자
"I left my phone on the left side of the room"
첫 번째, left는 '남기고 갔다'는 뜻이고 두 번째 left는 '왼쪽'이라는 뜻이다. context를 기반으로 하기 때문에 양 옆을 기반으로 의미를 판단한다. 즉, 문맥에 따라 임베딩이 달라져서 Contextualized Word Embedding라고 한다.
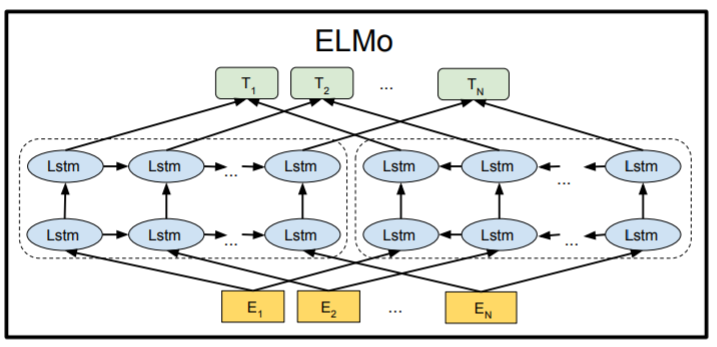
위의 그림은 Lstm이라는 Neural Network 기반의 모델이다. Lstm을 첫 번째 인풋(E1)에 weight를 더하거나 곱하고 해서 hidden으로 들어간다. 그리고 두 번째 input(단어)이 계산 후 hidden으로 들어갈 때는 첫 번째 단어에서 계산한 것을 반영해서 들어간다. 즉, 각각의 단어가 독립적으로 hidden layer에서 training이 되는 게 아니라 이전 input 값이 다음 input의 hidden layer에 영향을 준다.
ELMo의 포인트는 단어가 가지고 있는 의미를 잘 캐취 하는 것뿐만 아니라 그 단어가 어떤 문맥에서 나왔는지 고려를 해서 의미를 캡처하는 모델을 만든 거다. 그러나 여기서도 2가지의 문제가 생긴다. 문장이 길어지고 문단으로 판단하거나 그런 경우에 처음에 나왔던 단어의 의미는 거의 없어진다. 단순히 가까이 있는 단어만 의미를 캡처한다 그렇기 때문에 한국어 같은 경우는 동사가 가장 늦게 나오므로 항상 가까이 있는 단어가 가장 의미 있는 단어가 아닐 수도 있다. 이러한 이유로 Lstm은 순서가 있는 데이터에게는 학습을 잘하지만 실제로 빈 순서가 있으면 학습을 잘하지 못한다. 그래서 나온 것이 Transformers이다.
"Transformers" as a Bidirectional Language Model
Bidirectional Encoder Representations from Transformers (BERT)
Transformers는 시퀀스에 들어있는 단어들 중에 어느 것이 특정 단어와 연관이 있는지가 순서가 기준이 아니라 각각의 단어들에 따라 다르다는 가정을 가지고 있다. 예를 들어 eat라는 단어가 나오고 그 후에 다른 이야기가 나오다가 마지막에 apple이라는 단어가 나왔다. eat과 apple이 관련 있는 단어라는 것을 데이터에서 배운다. 그러면 멀리 있더라도 둘이 서로 연관이 되어있다는 것을 캐취 하는 것이 Transformer고 self-attention이라고도 한다.
Bidirectional - ELMo에서는 방향성이 한쪽으로만 가는 모델이었다. 그러나 BERT에서는 양방향으로 다하는 것이 포인트다.

BERT는 2018 후반부에 나온 거라 아직 나온 지 얼마 안 됐다. 그리고 open AI에서 나온 GPT2는 논술 같이 글을 쓰는 건데 사람이랑 비슷하게 썻다. BERT는 다양항 테스크에서 쓰고 있다. GPT를 보면 hidden layer 하나하나가 transformer다. lstm의 취약점을 개선했다고 보면 된다. 그렇지만 openAI GPT를 보면 방향성이 한 방향이다. BERT에서는 transformer를 쓰고 양방향으로 이동한다.
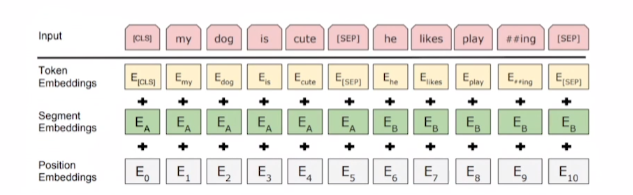
BERT input에 대한 그림이 위의 그림이다. 보통은 Embeddings와 같은데, BERT는 추가적으로 Position Embeddings가 들어간다. 왜냐하면 Bidirectional이라 단어의 위치를 알아야 모델링을 할 수 있다.
BERT usage
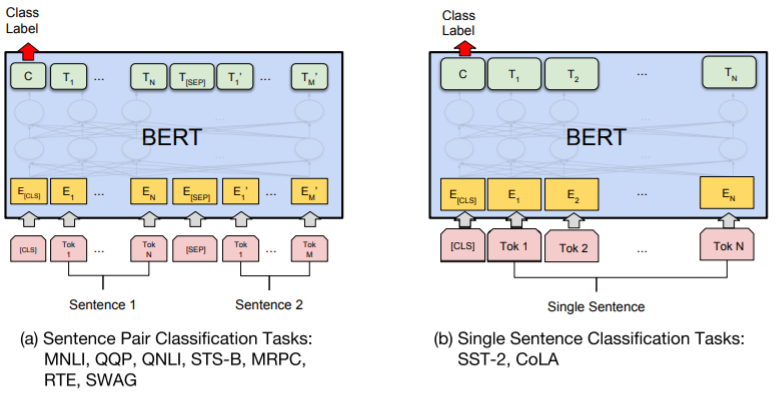
왼쪽 사진은 두 개의 sentence가 주어졌을 때 어떤 관계인지에 대한 task이고, 오른쪽은 긍, 부정에 관련된 task인가 확인하는 것에 도 사용된다.

왼쪽은 질문과 답을 주는 거나, 오른쪽은 각각의 단어에 tag(특정 분류에 따라 나누어 어디에 속하는지)을 다는 것이다.
버트와 자연어 처리의 흐름에 대해 조금 더 자세히 알고 싶다면 아래의 링크를 타면 된다.
자연어처리_BERT 기초개념(완전 초보용)
0. 들어가면서 기본적인 자연어 처리 흐름을 알기 위해서는 아래의 블로그에서 확인을 하자. han-py.tistory.com/249?category=942088 자연어처리 개념(RNN에서 BERT) 1. RNN (Recurrent Neural Network) RNN이..
han-py.tistory.com
그리고 버트는 transformer의 encoder로 이루어져 있다. TRANSFORMER에 대해 이해하려면 아래의 링크를 타면 된다.
자연어처리_TRANSFORMER
0. 들어가면서 'Attention is All You Need'라는 말에서 알 수 있 듯, Transformer은 Attention으로만 이루어져 있다. 기계 번역(언어 번역)을 예로 깊숙한 곳으로 조금씩 들어가 보려고 한다. 1. Model 위의..
han-py.tistory.com
'인공지능(Artificial Intelligence)' 카테고리의 다른 글
| 신경망(Neural Network) 기초 이해 (0) | 2020.10.28 |
|---|---|
| AI_Naive Bayes Classifier (0) | 2020.09.07 |
- Total
- Today
- Yesterday
- 자연어처리
- JavaScript
- typescript
- 자료구조
- Deque
- nodejs
- BFS
- react
- Express
- logout
- UserCreationForm
- Queue
- pandas
- Vue
- read_csv
- TensorFlow
- next.config.js
- react autoFocus
- nextjs autoFocus
- useState
- NextJS
- 클라우데라
- vuejs
- login
- error:0308010C:digital envelope routines::unsupported
- useHistory 안됨
- Python
- DFS
- mongoDB
- django
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |